
Trong phần này, chúng ta sẽ xây dựng chức năng tìm kiếm văn bản (full-text search) cho ứng dụng.
Để giúp cho bạn dễ theo dõi, sau đây là danh sách các bài viết trong loạt bài hướng dẫn này:
- Phần 1: Hello, World
- Phần 2: Tìm hiểu về template
- Phần 3: Tìm hiểu về Web Forms
- Phần 4: Sử dụng cơ sở dữ liệu
- Phần 5: Xử lý đăng nhập
- Phần 6: Hồ sơ cá nhân và ảnh đại diện
- Phần 7: Xử lý lỗi
- Phần 8: Tạo chức năng follower
- Phần 9: Phân trang
- Phần 10: Hỗ trợ email
- Phần 11: Nâng cấp giao diện
- Phần 12: Xử lý thời gian
- Phần 13: Hỗ trợ đa ngôn ngữ
- Phần 14: Sử dụng Ajax
- Phần 15: Tinh chỉnh cấu trúc ứng dụng
- Phần 16: Hỗ trợ tìm kiếm (Bài viết này)
- Phần 17: Triển khai ứng dụng trên Linux
- Phần 18: Triển khai ứng dụng với Heroku
- Phần 19: Triển khai ứng dụng với Docker
- Phần 20: JavaScript nâng cao
- Phần 21: Thông báo cho người sử dụng
- Phần 22: Tìm hiểu về tác vụ nền
- Phần 23: Xây dựng API
Bạn có thể truy cập mã nguồn cho phần này tại GitHub.
Mục tiêu chính của phần này là xây dựng chức năng tìm kiếm cho Myblog để user có thể tìm các bài viết bằng ngôn ngữ thường nhật. Đối với nhiều loại Web site, chúng ta có thể để cho Google, Bing lập chỉ mục cho nội dung và cung cấp kết quả tìm kiếm qua các API. Cách này hoạt động tốt với các site mà phần lớn các trang Web có nội dung tĩnh. Nhưng trong ứng dụng của chúng ta, đơn vị nội dung cơ bản là các bài viết và chỉ chiếm một phần nhỏ của các trang Web chứa chúng. Do đó, chúng ta chỉ muốn kết quả tìm kiếm là các bài viết này chứ không phải toàn bộ các trang liên quan. Ví dụ như khi chúng ta tìm kiếm cụm từ “thời tiết”, chúng ta muốn thấy các bài viết từ bất kỳ user nào có sử dụng cụm từ này. Rõ ràng là một trang có tất cả các bài viết với cụm từ “thời tiết” (hay bất kỳ một từ khóa nào khác) không phải là một trang thật sự trong ứng dụng và vì vậy, không thể được lập chỉ mục bởi các cơ chế tìm kiếm. Vì vậy, chúng ta không có cách nào khác hơn là phải tự xây dựng cơ chế tìm kiếm riêng của mình.
Giới thiệu các giải pháp tìm kiếm văn bản (Full-Text Search Engine)
Các giải pháp hỗ trợ cho việc tìm kiếm văn bản không được chuẩn hóa như các cơ sở dữ liệu quan hệ. Có nhiều lựa chọn khác nhau trong thế giới mã nguồn mở cho mục đích này: Elasticsearch, Apache Solr, Woosh, Xapian, Sphinx, … Thêm vào đó, một số cơ sở dữ liệu cũng hỗ trợ việc tìm kiếm với các tính năng tương tự như các giải pháp trên. SQLite, MySQL và PostgreSQL đều hỗ trợ cho việc tìm văn bản ở mức độ nhất định, các cơ sở dữ liệu NoSQL như MongoDB và CouchDB cũng có chức năng này.
Nếu bạn muốn biết cơ chế tìm kiếm nào trên đây làm việc được với các ứng dụng Flask thì câu trả lời là toàn bộ! Đây là một ưu điểm của Flask – làm việc không theo cảm tính. Vậy thì giải pháp nào mới là lựa chọn tốt nhất?
Trong danh sách các giải pháp tìm kiếm văn bản, Elasticsearch có vẻ nổi bật hơn cả vì nó rất phổ biến, một phần vì nó là thành phần chữ “E” nằm trong bộ ba nổi tiếng ELK (Elasticsearch, Logstash và Kibana) để lập chỉ mục cho nhật ký hệ thống. Việc sử dụng tính năng tìm kiếm trong cơ sở dữ liệu cũng có thể là một lựa chọn tốt, nhưng bởi vì SQLAlchemy không hỗ trợ cho chức năng này, chúng ta phải xử lý việc tìm kiếm với các câu lệnh SQL trực tiếp hoặc là tìm một gói khác có hỗ trợ các thao tác tìm kiếm văn bản cấp cao và làm việc song song với SQLAlchemy.
Vì các lý do trên, chúng ta sẽ sử dụng Elasticsearch. Nhưng chúng ta sẽ xây dựng mã cho quá trình lập chỉ mục và các hàm tìm kiếm sao cho chúng ta có thể chuyển đổi dễ dàng sang các cơ chế tìm kiếm khác. Điều này sẽ giúp bạn thay thế Elasticsearch bằng cơ chế tìm kiếm của bạn mà không tốn nhiều công sức để sửa đổi mã nguồn.
Cài đặt Elasticsearch
Elasticsearch có thể được cài đặt bằng nhiều phương pháp khác nhau: sử dụng trình cài đặt tự động hoặc cài đặt thủ công với các file nhị phân, hoặc với Docker. Bạn có thể làm theo hướng dẫn chi tiết trên trang tài liệu của Elasticsearch để cài đặt. Nếu bạn đang sử dụng Linux, bạn cũng có thể cài đặt với các gói có sẵn trong bản phân phối Linux của bạn. Tuy nhiên, nếu bạn sử dụng Linux thì cách cài đặt dễ dàng nhất là sử dụng Docker theo hướng dẫn trong trang tài liệu của Elasticsearch.
Sau khi đã cài đặt Elasticsearch, bạn có thể kiểm tra nó có hoạt động hay không bằng cách nhập vào địa chỉ http://localhost:9200 vào thanh địa chỉ trong trình duyệt của bạn. Nếu quá trình cài đặt thành công, bạn sẽ thấy một số thông tin trả về theo định dạng JSON. Vì chúng ta sẽ sử dụng Elasticsearch với Python, chúng ta cũng cần cài đặt thư viện Python hỗ trợ:
|
1 |
(myenv) $ pip3 install elasticsearch |
Bạn cũng sẽ cần cập nhật file requirements.txt:
|
1 |
(myenv) $ pip3 freeze > requirements.txt |
Cách sử dụng Elasticsearch
Chúng ta sẽ đi qua một số các thao tác cơ bản với Elasticsearch từ cửa sổ lệnh của Python để giúp bạn làm quen với phần mềm này và cũng giúp bạn hiểu các chi tiết trong mã nguồn mà chúng ta sẽ thảo luận ở phần sau.
Để tạo kết nối với Elasticsearch, chúng ta cần tạo ra một thực thể của lớp Elasticsearch và truyền cho nó một tham số là địa chỉ kết nối:
|
1 2 |
>>> from elasticsearch import Elasticsearch >>> es = Elasticsearch('http://localhost:9200') |
Dữ liệu trong Elasticsearch được lưu trong các chỉ mục (index). Không như các cơ sở dữ liệu quan hệ, dữ liệu ở đây chỉ là các đối tượng JSON. Ví dụ sau đây sẽ lưu một đối tượng (hay một tài liệu theo thuật ngữ của Elasticsearch) gọi là text vào một chỉ mục gọi là my_index:
|
1 |
>>> es.index(index='my_index', id=1, body={'text': 'this is a test'}) |
Trong quá trình lưu, Elasticsearch cần một ID duy nhất và dữ liệu dạng JSON cho mỗi tài liệu.
Tiếp theo, chúng ta sẽ tiến hành lưu tài hiệu thứ hai vào chỉ mục này:
|
1 |
>>> es.index(index='my_index', id=2, body={'text': 'a second test'}) |
Đến đây, chúng ta có hai tài liệu trong chỉ mục này và có thể tiến hành tìm kiếm. Trong ví dụ dưới đây, chúng ta sẽ thử tìm các tài liệu có chứa từ khóa this test:
|
1 |
>>> es.search(index='my_index', body={'query': {'match': {'text': 'this test'}}}) |
Hàm es.search() sẽ trả về một từ điển dữ liệu Python với kết quả tìm kiếm:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ 'took': 63, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': { 'total': { 'value': 2, 'relation': 'eq' }, 'max_score': 0.82712996, 'hits': [ { '_index': 'my_index', '_type': 'my_index', '_id': '1', '_score': 0.82712996, '_source': {'text': 'this is a test'} }, { '_index': 'my_index', '_type': 'my_index', '_id': '2', '_score': 0.19363809, '_source': {'text': 'a second test'} } ] } } |
Như bạn thấy, kết quả tìm kiếm ở đây gồm có hai tài liệu và được gán một số điểm (score) nhất định. Tài liệu có điểm cao nhất có chứa hai từ mà chúng ta đã tìm trong khi tài liệu thứ hai chỉ chứa một từ. Nhưng ngay cả tài liệu thứ nhất cũng không có điểm cao vì cụm từ trả về không hoàn toàn trùng khớp với cụm từ đang được tìm.
Sau đây là một kết quả khác khi chúng ta thử tìm với từ khóa second
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
>>> es.search(index='my_index', body={'query': {'match': {'text': 'second'}}}) { 'took': 5, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': { 'total': { 'value': 1, 'relation': 'eq' }, 'max_score': 0.7361701, 'hits': [ { '_index': 'my_index', '_type': 'my_index', '_id': '2', '_score': 0.7361701, '_source': {'text': 'a second test'} } ] } } |
Điểm cho tài liệu được tìm thấy tương đối thấp vì từ khóa không hoàn toàn khớp với văn bản trong tài liệu. Tuy nhiên, vì chỉ có một văn bản có chứa từ “second”, văn bản còn lại không có trong kết quả tìm kiếm.
Đối tượng truy vấn trong Elasticsearch còn có các tùy chọn khác như là phân trang và sắp xếp như trong các cơ sở dữ liệu quan hệ. Bạn có thể tìm hiểu thêm về các tùy chọn này tại trang tài liệu trực tuyến của Elasticsearch. Bạn có thể thử thêm các tài liệu mới vào chỉ mục và các chọn lựa tìm kiếm khác nhau. Sau khi hoàn tất, bạn có thể xóa chỉ mục với lệnh sau đây:
|
1 |
>>> es.indices.delete('my_index') |
Cấu hình cho Elasticsearch
Tích hợp Elasticsearch vào ứng dụng là minh họa tốt nhất cho khả năng của Flask. Đây là một dịch vụ hỗ trợ và gói Python không liên quan đến Flask, nhưng chúng ta vẫn có thể sử dụng với Flask mà không gặp trở ngại đáng kể nào. Để tích hợp Elasticsearch vào ứng dụng, chúng ta bắt đầu với việc cấu hình trong từ điển app.config:
config.py: Cấu hình cho Elasticsearch.
|
1 2 3 |
class Config(object): ... ELASTICSEARCH_URL = os.environ.get('ELASTICSEARCH_URL') |
Như hầu hết các tham số cấu hình khác, địa chỉ kết nối cho Elasticsearch sẽ được lưu trong một biến môi trường. Nếu biến môi trường này không được định nghĩa hoặc tìm thấy, chúng ta sẽ gán tham số cấu hình này là None và Elasticsearch sẽ không hoạt động. Nhờ kỹ thuật này, chúng ta không cần phải cho Elasticsearch chạy thường xuyên mà chỉ khi nào chúng ta cần sử dụng mà thôi. Khi chúng ta cần chạy Elasticsearch, chúng ta sẽ định nghĩa biến môi trường ELASTICSEARCH_URL trực tiếp từ cửa sổ lệnh hay từ file .env như sau:
|
1 |
ELASTICSEARCH_URL=http://localhost:9200 |
Điều bất tiện khi sử dụng Elasticsearch là nó không có thư viện mở rộng nào của Flask để hỗ trợ. Chúng ta không thể tạo thực thể cho Elasticsearch ở mức toàn cục như trong ví dụ trên vì để khởi tạo nó chúng ta cần truy cập đến app.config, nhưng đối tượng này chỉ hiện hữu sau khi hàm create_app() được gọi. Vì vậy, chúng ta sẽ phải thêm một thuộc tính elasticsearch vào thực thể app trong hàm tạo ứng dụng:
app/__init__.py: Thực thể Elasticsearch
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... from elasticsearch import Elasticsearch ... def create_app(config_class=Config): app = Flask(__name__) app.config.from_object(config_class) ... app.elasticsearch = Elasticsearch([app.config['ELASTICSEARCH_URL']]) \ if app.config['ELASTICSEARCH_URL'] else None ... |
Việc thêm thuộc tính vào thực thể app dường như hơi kỳ lạ. Nhưng các đối tượng Python không có giới hạn về cấu trúc và cho phép thêm các thuộc tính mới vào bất kỳ thời điểm nào. Một cách nữa mà bạn có thể thử là tạo ra một lớp con của Flask và định nghĩa thuộc tính elasticsearch trong hàm __init__() của lớp này.
Bạn cũng nên lưu ý cách chúng ta sử dụng biểu thức điều kiện (condition expression) để gán giá trị None cho thực thể Elasticsearch khi không tìm thấy địa chỉ kết nối đến Elasticsearch từ biến môi trường.
Xây dựng kiến trúc tổng quát cho tác vụ tìm kiếm văn bản
Như đã nói trong phần mở đầu, chúng ta muốn xây dựng một giải pháp cho phép chúng ta dễ dàn chuyển đổi từ Elasticsearch sang các phần mềm tìm kiếm văn bản khác, và chúng ta cũng không muốn tạo ra các tính năng riêng cho việc tìm kiếm các bài viết mà sẽ thiết kế một giải pháp giúp cho chúng ta có thể dễ dàng mở rộng sang các mô hình dữ liệu khác nếu cần thiết. Vì các lý do này, chúng ta sẽ xây dựng một lớp trừu tượng (abstraction) cho chức năng tìm kiếm. Ý tưởng của chúng ta là thiết kế các chức năng một cách tổng quát và không giới hạn trong việc lập chỉ mục cho các mô hình dữ liệu kiểu Post hoặc chỉ dùng Elasticsearch cho việc tìm kiếm. Làm sao chúng ta có thể làm điều này?
Việc đầu tiên chúng ta cần làm là tìm cách tổng quát để chỉ định các mô hình dữ liệu và các trường phụ thuộc cần được lập chỉ mục. Để đạt mục đích này, chúng ta sẽ bắt buộc các mô hình dữ liệu cần được lập chỉ mục phải định nghĩa thuộc tính lớp __searchable__ để liệt kê các trường cần được lập chỉ mục. Cụ thể là trong mô hình dữ liệu Post, chúng ta sẽ thực hiện thay đổi như sau:
app/models.py: Thêm một thuộc tính __searchable__ vào mô hình dữ liệu Post.
|
1 2 3 |
class Post(db.Model): __searchable__ = ['body'] ... |
Với thay đổi này, chúng ta định nghĩa rằng trường body trong mô hình dữ liệu này cần được lập chỉ mục trong phần mềm tìm kiếm. Cũng cần nói thêm rằng thuộc tính __searchable__ chỉ là một biến mà không có hành vi nào kèm theo. Nó chỉ giúp chúng ta tạo ra các hàm lập chỉ mục theo cách tổng quát.
Chúng ta sẽ đưa toàn bộ các hàm tương tác với chỉ mục của Elasticsearch vào module app/search.py. Bằng cách này, chúng ta có thể gói gọi toàn bộ mã nguồn liên quan đến Elasticsearch trong module này. Phần còn lại của ứng dụng sẽ sử dụng các hàm trong module mới này để truy cập chỉ mục và không có quyền truy cập trực tiếp đến Elasticsearch. Điều này rất quan trọng bởi vì nếu khi nào đó chúng ta quyết định thay thế Elasticsearch bằng một phần mềm tìm kiếm khác, tất cả những gì chúng ta cần làm là viết lại các hàm trong module này và ứng dụng sẽ không bị ảnh hưởng gì.
Để hỗ trợ cho việc tìm kiếm trong Myblog, chúng ta sẽ tạo ba hàm liên quan đến các chỉ mục: Thêm các tài liệu mới vào một chỉ mục có sẵn, xóa bỏ các tài liệu trong chỉ mục (giả sử rằng đến lúc nào đó chúng ta sẽ cho phép chức năng xóa bài viết), và thực hiện một truy vấn (search query). Sau đây là mã nguồn của module app/search.py với ba hàm trên cho Elasticsearch và sử dụng các chức năng chúng ta đã thấy khi tương tác với Elasticsearch qua cửa sổ lệnh của Python:
app/search.py: Các hàm tìm kiếm
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from flask import current_app def add_to_index(index, model): if not current_app.elasticsearch: return payload = {} for field in model.__searchable__: payload[field] = getattr(model, field) current_app.elasticsearch.index(index=index, id=model.id, body=payload) def remove_from_index(index, model): if not current_app.elasticsearch: return current_app.elasticsearch.delete(index=index, id=model.id) def query_index(index, query, page, per_page): if not current_app.elasticsearch: return [], 0 search = current_app.elasticsearch.search( index=index, body={'query': {'multi_match': {'query': query, 'fields': ['*']}}, 'from': (page - 1) * per_page, 'size': per_page}) ids = [int(hit['_id']) for hit in search['hits']['hits']] return ids, search['hits']['total']['value'] |
Các hàm này đều bắt đầu với điều kiện nếu app.elasticsearch là None, và nếu điều kiện này đúng thì sẽ chấm dứt mà không làm gì thêm. Điều này để đảm bảo rằng nếu Elasticsearch không được cấu hình đúng, ứng dụng của chúng ta sẽ tiếp tục thực thi mà không báo lỗi dù không có chức năng tìm kiếm. Việc này sẽ giúp chúng ta thuận lợi hơn trong quá trình viết mã hoặc khi chạy các đoạn mã kiểm tra.
Các hàm này sẽ nhận tham số đầu tiên là tên chỉ mục. Khi gọi các chức năng từ Elasticsearch, chúng ta sẽ dùng tham số này làm tên chỉ mục và đồng thời cũng là kiểu tài liệu như trong ví dụ với cửa sổ lệnh Python ở trên.
Các hàm thêm và xóa tài liệu từ chỉ mục sẽ nhận tham số thứ hai là mô hình dữ liệu SQLAlchemy. Hàm add_to_index() sử dụng biến __searchable__ mà chúng ta đã thêm vào mô hình dữ liệu để tạo tài liệu được thêm vào chỉ mục. Nếu bạn còn nhớ, các tài liệu của Elasticsearch cũng cần một định danh duy nhất (unique identifier). Chúng ta sẽ sử dụng trường id trong mô hình dữ liệu của SQLAlchemy để làm định danh này vì nó cũng đáp ứng được yêu cầu về tính duy nhất. Việc sử dụng cùng một giá trị id cho cả SQLAlchemy và Elasticsearch rất hữu ích khi thực hiện việc tìm kiếm vì nó cho phép chúng ta liên kết các dữ liệu trong hai cơ sở dữ liệu. Còn một việc chúng ta chưa đề cập đến là nếu bạn thêm một tài liệu với một id có sẵn, Elasticsearch sẽ thay thế tài liệu cũ bằng tài liệu mới, vì vậy hàm add_to_index() có thể được sử dụng cho cả hai mục đích thêm và cập nhật tài liệu.
Trong hàm remove_from_index(), việc gọi phương thức es.delete() sẽ xóa bỏ một tài liệu có id tương ứng trong chỉ mục của Elasticsearch. Đây cũng là ví dụ điển hình để cho thấy lợi ích khi sử dụng cùng một giá trị id cho SQLAlchemy và Elasticsearch.
Hàm query_index() nhận vào các tham số là tên chỉ mục và cụm văn bản cần tìm cùng với các tham số cho việc phân trang. Nhờ đó kết quả tìm kiếm có thể được phân thành các trang riêng biệt tương tự như chức năng phân trang của Flask-SQAlchemy cho kết quả truy vấn dữ liệu mà chúng ta đã sử dụng trước đây trong Phần 9. Bạn đã thấy qua ví dụ sử dụng phương thức es.search() từ cửa sổ lệnh Python ở trên. Cách gọi hàm ở đây cũng gần giống như vậy, nhưng thay vì sử dụng kiểu truy vấn match, chúng ta sử dụng kiểu multi_match để tìm trên nhiều trường khác nhau. Khi sử dụng tên trường là *, chúng ta yêu cầu Elasticsearch tìm trên tất cả các trường – cũng đồng nghĩa với việc chúng ta thực hiện tìm kiếm trên toàn bộ chỉ mục. Điều này sẽ giúp cho hàm mang tính tổng quát bởi vì các mô hình dữ liệu khác nhau có thể có các tên trường khác nhau trong chỉ mục.
Tham số body trong hàm es.search() cũng bao gồm các tham số về phân trang ngoài tham số chính là truy vấn. Các tham số from và size quyết định tập hợp con nào của kết quả tìm kiếm sẽ được trả về. Elasticsearch không cung cấp một đối tượng Pagination để chúng ta có thể dễ dàng sử dụng như với Flask-SQLAlchemy, vì vậy, chúng ta phải làm một số phép tính để tìm ra tập hợp thích hợp đại diện cho trang tương ứng từ giá trị from.
Lệnh return trong hàm query_index() tương đối phức tạp. Nó trả về hai giá trị: thứ nhất là một danh sách các id trong kết quả tìm kiếm, và thứ hai là tổng số tài liệu trong kết quả tìm kiếm. Cả hai giá trị này được trích ra từ từ điển Python do hàm es.search() trả về. Trong trường hợp bạn không quen với biểu thức chúng ta sử dụng để lấy danh sách các ID, đây là một đặc điểm tuyệt vời của Python gọi là list comprehension để biến đổi một danh sách thành một danh sách khác. Trong trường hợp này, chúng ta sử dụng list comprehension để lấy các id trong kết quả tìm kiếm từ Elasticsearch.
Nếu bạn cảm thấy bổi rối vì các thông tin ở trên, có lẽ một số ví dụ với cửa sổ lệnh Python sẽ giúp bạn hiểu rõ hơn. Trong các ví dụ sau đây, chúng ta sẽ thêm các bài viết từ cơ sở dữ liệu vào chỉ mục của Elasticsearch bằng cách thủ công. Trong cơ sở dữ liệu kiểm tra, chúng ta có một số bài viết với các từ “một”, “hai”, “ba”, “bốn” và “năm” trong đó. Chúng ta sẽ dùng các từ này để làm từ khóa tìm kiếm. Nếu cơ sở dữ liệu của bạn không giống như vậy, bạn sẽ cần phải thay đổi từ khóa cho thích hợp:
|
1 2 3 4 5 6 7 8 9 10 11 |
>>> from app.search import add_to_index, remove_from_index, query_index >>> for post in Post.query.all(): ... add_to_index('posts', post) >>> query_index('posts', ' một hai ba bốn năm', 1, 100) ([13, 14, 15, 12, 17, 6, 11, 16], 8) >>> query_index('posts', ' một hai ba bốn năm', 1, 3) ([13, 14, 15], 8) >>> query_index('posts', ' một hai ba bốn năm', 2, 3) ([12, 17, 6], 8) >>> query_index('posts', ' một hai ba bốn năm', 3, 3) ([11, 16], 8) |
Truy vấn chúng ta thực hiện trong các ví dụ trên trả về tám kết quả. Khi thực hiện truy vấn đầu tiên, húng ta yêu cầu trang 1 với 100 kết quả mỗi trang nên chúng ta sẽ thấy cả tám kết quả. Nhưng trong ba truy vấn tiếp theo, chúng ta thử tiến hành phân trang các kết quả này tương tự như chúng ta đã thực hiện với Flask-SQLAlchemy ngoại trừ việc các kết quả là một danh sách các ID thay vì các đối tượng SQLAlchemy.
Sau đó, nếu bạn muốn cho cơ sở dữ liệu của bạn trở lại trạng thái ban đầu, bạn có thể xóa bỏ các chỉ mục cho các bài viết như sau:
|
1 |
>>> app.elasticsearch.indices.delete('posts') |
Tích hợp chức năng tìm kiếm với SQLAlchemy
Giải pháp trên của chúng ta cũng tạm ổn, nhưng vẫn còn một vài vấn đề. Rõ ràng nhất là kết quả trả về dưới dạng một danh sách các ID. Điều này rất bất tiện vì cái chúng ta thực sự cần là các mô hình dữ liệu SQLAlchemy mà các template cần để hiển thị. Vì vậy chúng ta phải tìm cách để chuyển đổi danh sách này sang các mô hình dữ liệu tương ứng. Vấn đề này có thể được giải quyết bằng cách tạo ra một truy vấn SQLAlchemy để lấy các đối tượng tương ứng từ cơ sở dữ liệu bằng Id của chúng. Trên lý thuyết thì điều này rất dễ giải quyết, nhưng trong thực tế thì việc viết một truy vấn đơn bằng SQLALchemy để thực hiện việc này tương đối khó.
Vấn đề thứ hai là giải pháp này đòi hỏi chúng ta phải gọi hàm lập chỉ mục riêng rẽ (explicit) mỗi khi thêm hoặc xóa bỏ một bài viết trong hệ thống. Thật ra thì phương pháp này cũng không quá tệ, nhưng cũng không phải là hoàn hảo, bởi vì trong quá trình thực thi, một lỗi dẫn đến việc hàm lập chỉ mục không được gọi khi dữ liệu được cập nhật với SQLAlchemy rất khó được phát hiện và sẽ làm cho hệ thống chỉ mục của Elasticsearch và cơ sở dữ liệu ứng dụng của chúng ta không còn đồng bộ với nhau. Giải pháp tốt hơn cho vấn đề này là kích hoạt việc gọi hàm lập chỉ mục một cách tự động mỗi khi cơ sở dữ liệu của ứng dụng được cập nhật bởi SQLAlchemy.
Để tự động hóa việc kích hoạt hàm lập chỉ mục, chúng ta sẽ sử dụng các sử kiện SQLAlchemy để điều khiển việc gọi hàm này. SQLAlchemy cung cấp một danh sách dài các sự kiện mà ứng dụng có thể sử dụng. Ví dụ như chúng ta có thể thiết lập sao cho mỗi khi một phiên làm việc (session) được xác nhận thực thi (commit), SQLAlchemy sẽ tự động gọi một hàm nào đó trong ứng dụng của chúng ta, và hàm này sẽ chịu trách nhiệm cập nhật chỉ mục cho Elasticsearch với các thông tin liên quan.
Để giái quyết hai vấn đề trên, chứng ta sẽ dùng một lớp mixin. Nếu bạn còn nhớ, trong Phần 5, chúng ta có thêm lớp UserMixin từ thư viện Flask-Login vào mô hình User để sử dụng một số chức năng mà Flask-Login cần. Để hỗ trợ cho chức năng tìm kiếm, chúng ta sẽ định nghĩa lớp SearchableMixin của riêng chúng ta. Lớp này sẽ có tác dụng cung cấp các phương thức cần thiết cho lớp sử dụng nó để quản lý các chỉ mục kèm theo. Lớp mixin này sẽ là chất kết dính giữa SQLAlchemy và Elasticsearch và giải quyết các rắc rối mà chúng ta vừa đề cập ở trên.
Để hiểu rõ hơn về lớp mixin này, chúng ta sẽ xem xét mã nguồn dưới đây và thảo luận một số chi tiết quan trọng. Lưu ý rằng chúng ta sẽ sử dụng một số kỹ thuật cao cấp trong lớp này. Vì vậy, bạn cần đọc kỹ để hiểu mã nguồn bên dưới:
app/models.py: Lớp SearchableMixin
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
from app.search import add_to_index, remove_from_index, query_index class SearchableMixin(object): @classmethod def search(cls, expression, page, per_page): ids, total = query_index(cls.__tablename__, expression, page, per_page) if total == 0: return cls.query.filter_by(id=0), 0 when = [] for i in range(len(ids)): when.append((ids[i], i)) return cls.query.filter(cls.id.in_(ids)).order_by( db.case(when, value=cls.id)), total @classmethod def before_commit(cls, session): session._changes = { 'add': list(session.new), 'update': list(session.dirty), 'delete': list(session.deleted) } @classmethod def after_commit(cls, session): for obj in session._changes['add']: if isinstance(obj, SearchableMixin): add_to_index(obj.__tablename__, obj) for obj in session._changes['update']: if isinstance(obj, SearchableMixin): add_to_index(obj.__tablename__, obj) for obj in session._changes['delete']: if isinstance(obj, SearchableMixin): remove_from_index(obj.__tablename__, obj) session._changes = None @classmethod def reindex(cls): for obj in cls.query: add_to_index(cls.__tablename__, obj) db.event.listen(db.session, 'before_commit', SearchableMixin.before_commit) db.event.listen(db.session, 'after_commit', SearchableMixin.after_commit) |
Lớp này bao gồm bốn phương thức tĩnh (class method hay static method trong các ngôn ngữ lập trình khác). Nếu bạn còn nhớ thì các phương thức tĩnh là các phương thức được liên kết với lớp chứ không phải một thực thể nào của lớp đó. Bạn có thể thấy chúng ta sử dụng tham số cls thay vì self để phân biệt rằng các phương thức này sẽ nhận cá lớp thay vì một thực thể của lớp trong tham số đầu tiên. Cụ thể như sau khi được kết nối với lớp Post, phương thức search() trên đây sẽ được gọi thông qua biếu thức Post.search() mà không cần phải có một thực thể của lớp Post.
Phương thức tĩnh search() sẽ gọi hàm query_index() từ app/search.py để thay thế danh sách các ID bằng các đối tượng tương ứng. Bạn có thể thấy lệnh đầu tiên trong hàm này dùng để gọi query_index() và truyền giá trị cls.__tablename__ cho tham số index để dùng làm tên chỉ mục. Đây cũng là quy ước mà chúng ta sẽ sử dụng, tất cả các chỉ mục sẽ được đặt tên theo tên của các bản mà Flask-SQLAlchemy sử dụng. Hàm này trả về một danh sách các ID và tổng số các kết quả tìm kiếm. Truy vấn được SQLAlchemy sử dụng để lấy danh sách các đối tượng tương ứng (các mô hình dữ liệu) từ ID của chúng sử dụng biểu thức CASE của ngôn ngữ SQL để bảo đảm rằng các kết quả được sắp xếp theo đúng thứ tự của danh sách ID được truyền vào. Điều này rất quan trọng vì kết quả tìm kiếm của Elasticsearch được sắp đặt theo thứ tự liên quan đến từ khóa từ nhiều đến ít. Nếu bạn muốn tìm hiểu cách hoạt động của truy vấn này, bạn có thể đọc trong phần trả lời của câu hỏi này trên StackOverflow. Cuối cùng, hàm search() sẽ trả về danh sách các đối tượng này.
Các phương thức before_commit() và after_commit() sẽ được gọi khi hai sự kiện (event) tương ứng từ SQLAlchemy được kích hoạt: trước và sau khi có xác nhận thực thi (commit) dữ liệu vào cơ sở dữ liệu. Hàm xử lý trước khi dữ liệu được commit rất hữu ích vì đây là thời điểm dữ liệu còn chưa được cập nhật trong cơ sở dữ liệu, do đó chúng ta có thể phân tích và tìm ra các đối tượng sẽ được thêm vào, sửa đổi hoặc xóa bỏ khỏi cơ sở dữ liệu bên trong các đối tượng tương ứng là session.new, session.dirty và session.deleted. Sau khi dữ liệu đã được lưu (commit) vào cơ sở dữ liệu, các đối tượng này sẽ không còn tồn tại, vì vậy chúng ta phải lưu lại chúng trước khi quá trình lưu được thực thi. Chúng ta sẽ sử dụng từ điển session._changes để chứa các đối tượng này và sử dụng chúng để cập nhật chỉ mục của Elasticsearch sau khi quá trình commit hoàn tất. Toàn bộ quá trình này được minh họa trong sơ đồ dưới đây:
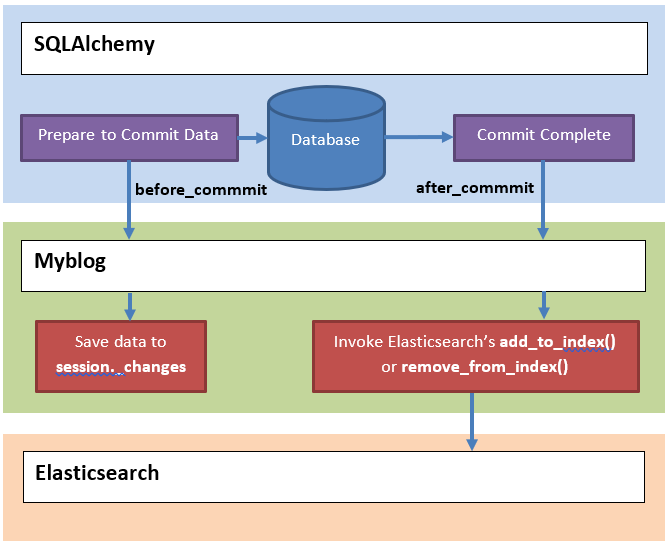
Khi hàm after_commit() được gọi, toàn bộ dữ liệu đã được lưu vào cơ sở dữ liệu. Do đó, đây là lúc thích hợp để cập nhật chỉ mục của Elasticsearch với các thay đổi tương ứng trong cơ sở dữ liệu. Vì trước đó, chúng ta đã lưu các dữ liệu được cập nhật trong biến _changes của đối tượng session khi hàm before_commit() được gọi, chúng ta có thể dùng các dữ liệu này trong các hàm lập chỉ mục trong module app/search.py cho các đối tượng có dùng lớp SearchableMixin.
Phương thức reindex() chỉ là một hàm hỗ trợ đơn giản để tạo chỉ mục cho toàn bộ dữ liệu trong cơ sở dữ liệu khi cần thiết. Chúng ta đã sử dụng kỹ thuật tương tự trong một phiên làm việc với cửa sổ lệnh Python trước đây để lập chỉ mục cho tất cả các bài viết vào chỉ mục “test” trong Elasticsearch. Với phương thức này, chúng ta có thể dùng lệnh Post.reindex() để lập chỉ mục cho tất cả bài viết trong cơ sở dữ liệu.
Sau định nghĩa lớp, chúng ta gọi hàm db.event.listen() trong SQLAlchemy hai lần. Lưu ý rằng các lần gọi này không nằm bên trong định nghĩa lớp mà nằm bên ngoài. Mục đích của các phát biểu này là để liên kết các hàm xử lý before_commit() và after_commit() trong lớp SearchableMixin với các sự kiện tương ứng của SQLAchemy. Nhờ đó, trong quá trình cập nhật dữ liệu, SQLAlchemy sẽ đồng thời kích hoạt các hàm này.
Và cuối cùng, để kết hợp lớp SearchableMixin với mô hình Post, chúng ta phải cho lớp Post kế thừa nó và kết hợp các sự kiện trước và sau khi dữ liệu được lưu lại trong cơ sở dữ liệu.
app/models.py: Kết hợp lớp SearchableMixin vào mô hình Post
|
1 2 |
class Post(SearchableMixin, db.Model): ... |
Đến đây, lớp Post đã có thể tự động tạo ra các chỉ mục tìm kiếm cho tất cả các bài viết. Chúng ta có thể gọi phương thức reindex() để khởi động quá trình lập chỉ mục cho các bài viết đang có sẵn trong cơ sở dữ liệu.
|
1 |
>>> Post.reindex() |
Chúng ta cũng có thể tìm các bài viết bằng phương thức Post.search(). Trong ví dụ dưới đây, chúng ta sẽ tìm và yêu cầu trả về trang đầu tiên với năm kết quả mỗi trang:
|
1 2 3 4 5 6 |
>>> query, total = Post.search('one two three four five', 1, 5) >>> total 7 >>> query.all() [<Post Bài viết số ba>, <Post Bài viết số bốn>, <Post Bài viết số năm >, <Post Bài viết số hai>, <Post Django là số hai>] |
Form tìm kiếm
Các giải pháp kỹ thuật mà chúng ta đã thảo luận từ đầu phần này khá phức tạp vì có liên quan đến một số các chủ đề nâng cao trong Python. Vì vậy, có lẽ bạn sẽ cần tìm hiểu một thời gian. Nhưng đến đây, có thể nói rằng chúng ta đã có một hệ thống hoàn chỉnh để tìm kiếm các bài viết với ngôn ngữ tự nhiên. Công việc còn lại của chúng ta trong phần này là tích hợp chức năng tìm kiếm này vào ứng dụng.
Cách xây dựng chức năng tìm kiếm khá phổ biến trên các trang Web là cung cấp gán từ khóa dùng để tìm kiếm vào tham số q trong địa chỉ của trang. Ví dụ nếu bạn muốn tìm kiếm từ Python trên Google và muốn tiết kiệm một vài giây, bạn có thể nhập địa chỉ sau đây vào thanh địa chỉ của trình duyệt để có kết quả trực tiếp:
|
1 |
https://www.google.com/search?q=python |
Bằng cách chèn từ khóa cần tìm vào địa chỉ, chúng ta có thể dễ dàng chia xẻ kết quả tìm kiếm với người khác và họ chỉ cần bấm vào địa chỉ này để thấy kết quả tìm kiếm tương ứng.
Hệ quả của kỹ thuật này là chúng ta sẽ sửa lại cách sử dụng web form như chúng ta đã làm trước đây. Cho đến thời điểm này, chúng ta luôn dùng các yêu cầu dạng POST để gởi dữ liệu trong form về máy chủ. Nhưng để xây dựng chức năng tìm kiếm theo cách ở trên, chúng ta sẽ gởi dữ liệu với yêu cầu dạng GET giống như khi chúng ta nhập địa chỉ vào thanh địa chỉ của trình duyệt hoặc bấm vào một liên kết. Ngoài ra, còn có một điểm khác nhau nữa cũng khá thú vị là form tìm kiếm sẽ được đặt trong thanh định hướng và được hiển thị trên tất cả các trang trong ứng dụng.
Sau đây là lớp đại diện cho form tìm kiếm với một trường duy nhất là trường văn bản q:
app/main/forms.py: Form tìm kiếm
|
1 2 3 4 5 6 7 8 9 10 11 |
from flask import request class SearchForm(FlaskForm): q = StringField(_l('Search'), validators=[DataRequired()]) def __init__(self, *args, **kwargs): if 'formdata' not in kwargs: kwargs['formdata'] = request.args if 'csrf_enabled' not in kwargs: kwargs['csrf_enabled'] = False super(SearchForm, self).__init__(*args, **kwargs) |
Có lẽ chúng ta không cần giải thích thêm về trường q vì nó cũng tương tự như các trường văn bản khác mà chúng ta đã dùng trước đây. Form này sẽ không có nút “Submit” bởi vì nếu form chỉ có một trường văn bản, trình duyệt sẽ tự động thực hiện việc gởi dữ liệu về máy chủ khi bạn bấm Enter ngay sau khi nhập văn bản, do đó, chúng ta không cần nút Submit trong trường hợp này. Chúng ta cũng thêm hàm khởi tạo __init__ để cung cấp giá trị cho các tham số formdata và crsf_enabled nếu các giá trị này không được trình duyệt cung cấp. Tham số formdata quyết định Flask-WTF sẽ lấy dữ liệu của form từ đâu. Theo mặc định, dữ liệu của form sẽ được lưu trong request.form nếu form được gởi đến máy chủ với yêu cầu dạng POST. Các form được gởi đến máy chủ qua các yêu cầu dạng GET sẽ chứa dữ liệu trong URL, vì vậy chúng ta cần báo với Flask-WTF để lấy dữ liệu của form qua biến request.args (biến này chứa các tham số trong URL). Và theo mặc định, các form được thiết lập để chống hình thức tấn công CRSF nhờ vào token CSRF được đóng gói qua hàm form.hidden_tag() trong template. Để các liên kết tìm kiếm có thể hoạt động được, chúng ta cần phải tắt thiết lập CSRF. Vì vậy, chúng ta sẽ gán csrf_enabled là False để Flask-WTF ngừng việc kiểm tra CSRF đối với các form này.
Vì chúng ta cần hiển thị form tìm kiếm này trên mọi trang trong ứng dụng, chúng ta cần tạo ra một thực thể của lớp SearchForm bất kể user đang ở trang nào trong ứng dụng với yêu cầu duy nhất là user phải đăng nhập, bởi vì hiện tại chúng ta không hiển thị bất kỳ nội dung nào cho các user không đăng nhập. Và thay vì tạo ra một đối tượng form cho mọi địa chỉ và truyền đối tượng này cho các template khác nhau, chúng ta sẽ sử dụng một mẹo rất hữu ích để tránh tình trạng trùng lặp mã nguồn khi cần xây dựng một chức năng xuyên suốt ứng dụng. Trước đây, chúng ta đã sử dụng hàm xử lý before_request trong Phần 6 để lưu lại thời điểm mỗi user truy cập ứng dụng lần cuối cùng. Chúng ta cũng sẽ tạo form tìm kiếm trong hàm này với một ít thay đổi:
app/main/routes.py: Khởi tạo form tìm kiếm trong hàm before_request
|
1 2 3 4 5 6 7 8 9 10 |
from flask import g from app.main.forms import SearchForm @bp.before_app_request def before_request(): if current_user.is_authenticated: current_user.last_seen = datetime.utcnow() db.session.commit() g.search_form = SearchForm() g.locale = str(get_locale()) |
Trong đoạn mã trên, chúng ta tạo ra một thực thể của lớp tìm kiếm khi chúng ta có một user được xác thực thành công. Và bởi vì chúng ta cần giữ cho đối tượng này tồn tại cho đến khi nó được hiển thị khi yêu cầu kết thúc, chúng ta cần lưu nó lại ở đâu đó trong ứng dụng. Và đối tượng g (bạn còn nhớ đối tượng này không?) có sẵn trong Flask là thích hợp nhất cho mục đích này vì nó có thể chứa các dữ liệu cần được sử dụng trong chu kỳ tồn tại của một yêu cầu. Ở đây, chúng ta lưu đối tượng form tìm kiếm này vào biến g.search_form. Nhờ vậy, khi hàm xử lý before_request hoàn thành và Flask tiếp tục gọi hàm hiển thị tương ứng với địa chỉ được yêu cầu, đối tượng g vẫn không thay đổi và vẫn còn lưu giữ đối tượng form tìm kiếm. Một điểm rất quan trọng cần lưu ý ở đây là mỗi một yêu cầu và mỗi user khác nhau sẽ được gán một đối tượng g riêng. Vì vậy, dù rằng máy chủ phải xử lý nhiều yêu cầu đồng thời từ các user khác nhau, bạn vẫn có thể sử dụng g để lưu các thông tin cho mỗi yêu cầu vì chúng độc lập với nhau.
Bước tiếp theo sẽ là hiển thị form này trên trang Web. Vì chúng ta muốn hiển thị form này trên mọi trang, chúng ta sẽ đặt nó vào trong than định hướng. Công việc này thật ra rất đơn giản bởi vì các template cũng có thể đọc các dữ liệu từ đối tượng g. Do đó, chúng ta không cần phải bận tâm về việc thêm một tham số vào hàm render_template() để truyền đối tượng tham form này đến các hàm hiển thị. Sau đây là cách chúng ta đặt form vào template gốc (base.html):
app/templates/base.html: Hiển thị form tìm kiếm trong thanh định hướng
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... <div class="collapse navbar-collapse" id="bs-example-navbar-collapse-1"> <ul class="nav navbar-nav"> ... Liên kết đến trang chủ và explore ... </ul> {% if g.search_form %} <form class="navbar-form navbar-left" method="get" action="{{ url_for('main.search') }}"> <div class="form-group"> {{ g.search_form.q(size=20, class='form-control', placeholder=g.search_form.q.label.text) }} </div> </form> {% endif %} ... |
Form chỉ được hiển thị khi nào biến g.search_form tồn tại. Việc kiểm tra này là cần thiết bởi vì một số trang như là trang báo lỗi sẽ không có định nghĩa của form này. Khai báo cho form cũng hơi khác so với các form mà chúng ta đã dùng trước đây. Chúng ta sẽ thiết lập thuộc tính method là get vì chúng ta muốn gởi dữ liệu tìm kiếm qua chuỗi URL với một yêu cầu dạng GET. Đồng thời chúng ta cũng khai báo thuộc tính action thay vì để trống như các form trước đây bởi vì các form mà chúng ta sử dụng trước đây sẽ gởi dữ liệu về cùng một địa chỉ của trang có chứa form. Nhưng form tìm kiếm là trường hợp đặc biệt vì nó xuất hiện trên tất cả các trang, vì vậy, chúng ta phải khai báo rõ là nó sẽ gởi dữ liệu về địa chỉ nào, và đó sẽ là một địa chỉ mới được dành riêng để xử lý các yêu cầu tìm kiếm.
Hàm hiển thị tìm kiếm
Mảnh ghép cuối cùng để hoàn thành việc tích hợp chức năng tìm kiếm vào ứng dụng là hàm hiển thị cho địa chỉ mà form sẽ gởi dữ liệu đến. Hàm hiển thị này sẽ được liên kết với địa chỉ /search, nhờ đó, bạn có thể gởi một yêu cầu tìm kiếm đến một địa chỉ như là http://localhost:5000/search?q=từ-cần-tìm tương tự như khi sử dụng Google.
app/main/routes.py: Hàm hiển thị tìm kiếm
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@bp.route('/search') @login_required def search(): if not g.search_form.validate(): return redirect(url_for('main.explore')) page = request.args.get('page', 1, type=int) posts, total = Post.search(g.search_form.q.data, page, current_app.config['POSTS_PER_PAGE']) next_url = url_for('main.search', q=g.search_form.q.data, page=page + 1) \ if total > page * current_app.config['POSTS_PER_PAGE'] else None prev_url = url_for('main.search', q=g.search_form.q.data, page=page - 1) \ if page > 1 else None return render_template('search.html', title=_('Search'), posts=posts, next_url=next_url, prev_url=prev_url) |
Trước đây, chúng ta đã sử dụng phương thức form.validate_on_submit() với các form để kiểm tra tính hợp lệ của dữ liệu nhập từ form. Thật không may là phương thức này chỉ hoạt động được với các form được gởi qua yêu cầu dạng POST. Vì vậy, trong form mới này chúng ta phải dùng hàm form.validate(). Hàm này chỉ giới hạn trong việc kiểm tra các giá trị nhập trong các trường của form mà không thể kiểm tra được dữ liệu được gởi như thế nào. Nếu quá trình kiểm tra thất bại thì cũng có nghĩa là user đã submit một form tìm kiếm mà không nhập từ khóa. Trong trường hợp đó, chúng ta sẽ tái định hướng user đến trang Explore có hiển thị tất cả các bài viết.
Phương thức Post.search() từ lớp SearchableMixin được dùng để lấy danh sách kết quả tìm kiếm. Chế độ phân trang được xử lý tương tự như cách chúng ta đã làm trong trang chủ và trang Explore, nhưng rắc rối hơn vì chúng ta không có đối tượng Pagination từ thư viện Flask-SQLAlchemy để hỗ trợ trong việc tạo ra các liên kết đến các trang trước và sau trang hiện hành. Vì vậy, chúng ta cần sử dụng đến giá trị trả về thứ hai của hàm Post.search() là tổng số các kết quả trong danh sách tìm kiếm.
Khi danh sách tìm kiếm và các liên kết phân trang trên trang hiện hành được tạo ra, chúng ta sẽ hiển thị toàn bộ các dữ liệu này trên template tương ứng. Chúng ta có thể tìm cách để sử dụng lại template index.html cho mục đích này. Nhưng vì một số khác biệt, chúng ta sẽ tạo ra một template hoàn toàn mới là search.html để hiển thị các kết quả tìm kiếm kèm theo template con _post.html để hiển thị kết quả tìm kiếm:
app/templates/search.html: Template hiển thị kết quả tìm kiếm
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
{% extends "base.html" %} {% block app_content %} <h1>{{ _('Search Results') }}</h1> {% for post in posts %} {% include '_post.html' %} {% endfor %} <nav aria-label="..."> <ul class="pager"> <li class="previous{% if not prev_url %} disabled{% endif %}"> <a href="{{ prev_url or '#' }}"> <span aria-hidden="true">←</span> {{ _('Previous results') }} </a> </li> <li class="next{% if not next_url %} disabled{% endif %}"> <a href="{{ next_url or '#' }}"> {{ _('Next results') }} <span aria-hidden="true">→</span> </a> </li> </ul> </nav> {% endblock %} |
Nếu bạn vẫn còn cảm thấy các logic dùng để tạo ra các liên kết đến các trang trước và sau trang hiện hành quá rắc rối, bạn có thể thử tham khảo tài liệu về thành phần phân trang của Bootstrap để hiểu rõ cơ chế hoạt động của nó.
Chắc rằng bạn cũng đồng ý là phần này dài và khá là khó nhằn phải không? Đúng là như vậy vì chúng ta đã đi qua một số kỹ thuật nâng cao và bạn cần có thời gian để hiểu. Điều quan trọng nhất bạn cần nhớ trong phần này là nếu bạn muốn sử dụng một cơ chế tìm kiếm khác thay vì Elasticsearch, việc duy nhất bạn cần làm là viết lại mã nguồn cho ba hàm trong app/search.py. Một lợi ích quan trọng nữa của các kiến thức mà chúng ta học được trong phần này là nếu chúng ta cần hỗ trợ cho một mô hình dữ liệu khác trong tương lại, chúng ta có thể làm được bằng cách đơn giản là thêm lớp SearchableMixin vào lớp đó, và thêm thuộc tính __searchable__ vào danh sách các trường cần được lập chỉ mục. Những gì chúng ta đã học trong phần này rất đáng giá vì từ đây chúng ta sẽ có thể làm việc với các cơ chế tìm kiếm văn bản một cách dễ dàng hơn nhiều.
Chúng ta sẽ tạm ngừng ở đây. Hẹn gặp bạn trong phần tiếp theo.
Mình đọc đến bài này và chạy thử chức năng tìm kiếm. Tuy vậy nó dường như bị lỗi:
elasticsearch.exceptions.NotFoundError: NotFoundError(404, ‘\n\n….
mình cũng bị giống bạn, debug ra thì nguyên nhân là cái index=’post’ chưa tồn tại trong elasticsearch, mình nghĩ là mỗi khi thêm bài post thì dữ liệu cũng sẽ được thêm vào elasticsearch thì elasticsearch mới có dữ liệu để truy vấn. xoá các bài post từ các bài học từ trước đến nay và thêm các bài post lại.