
Trong phần này, chúng ta sẽ cùng tìm hiểu về cách sử dụng cơ sở dữ liệu với ứng dụng Flask.
Để giúp cho bạn dễ theo dõi, sau đây là danh sách các bài viết trong loạt bài hướng dẫn này:
- Phần 1: Hello, World
- Phần 2: Tìm hiểu về template
- Phần 3: Tìm hiểu về Web Forms
- Phần 4: Sử dụng cơ sở dữ liệu (bài viết này)
- Phần 5: Xử lý đăng nhập
- Phần 6: Hồ sơ cá nhân và ảnh đại diện
- Phần 7: Xử lý lỗi
- Phần 8: Tạo chức năng follower
- Phần 9: Phân trang
- Phần 10: Hỗ trợ email
- Phần 11: Nâng cấp giao diện
- Phần 12: Xử lý thời gian
- Phần 13: Hỗ trợ đa ngôn ngữ
- Phần 14: Sử dụng Ajax
- Phần 15: Tinh chỉnh cấu trúc ứng dụng
- Phần 16: Hỗ trợ tìm kiếm
- Phần 17: Triển khai ứng dụng trên Linux
- Phần 18: Triển khai ứng dụng với Heroku
- Phần 19: Triển khai ứng dụng với Docker
- Phần 20: JavaScript nâng cao
- Phần 21: Thông báo cho người sử dụng
- Phần 22: Tìm hiểu về tác vụ nền
- Phần 23: Xây dựng API
Bạn có thể truy cập mã nguồn cho phần này tại GitHub.
Đây là một phần rất quan trọng vì hầu hết các ứng dụng đều cần đọc và lưu trữ dữ liệu một cách hiệu quả. Vì thế, chúng ta cần phải dùng đến cơ sở dữ liệu cho mục đích này.
Cơ sở dữ liệu trong Flask
Nếu bạn có tìm hiểu qua, bạn sẽ biết rằng Flask không hỗ trợ sẵn cơ sở dữ liệu. Tuy nhiên đây không phải là do sơ sót mà Flask được thiết kế như vậy để cho phép bạn chọn cơ sở dữ liệu nào thích hợp nhất cho ứng dụng của bạn thay vì bắt buộc bạn phải dùng một hệ cơ sở dữ liệu nào đó.
Các thư viện mở rộng trong Flask hỗ trợ cho việc sử dụng nhiều cơ sở dữ liệu khác nhau. Các hệ cơ sở dữ liệu có thể được chia thành hai nhóm chính: nhóm cơ sở dữ liệu theo mô hình quan hệ (relational) và nhóm còn lại không sử dụng mô hình này. Nhóm sau cũng được biết với tên gọi NoSQL bởi vì các hệ cơ sở dữ liệu trong nhóm này không sử dụng ngôn ngữ hỏi đáp SQL nối tiếng. Mặc dù cả hai nhóm đều có các đại diện xuất sắc, các hệ cơ sở dữ liệu trong nhóm đầu thích hợp hơn với các dữ liệu có cấu trúc như là danh sách người sử dụng, các bài viết … trong khi NoSQL thích hợp cho dữ liệu không có cấu trúc chặt chẽ. Ứng dụng của chúng ta có thể sử dụng các hệ cơ sở dữ liệu trong cả hai nhóm, nhưng chúng ta sẽ chọn cơ sở dữ liệu quan hệ theo như lý do đã nói ở trên.
Trong Phần 3, chúng ta đã sử dụng thư viện mở rộng đầu tiên trong Flask (còn nhớ Flask-WTF không?). Trong phần này, chúng ta sẽ sử dụng thêm hai thư viện mở rộng nữa. Thư viện đầu tiên là Flask-SQLAlchemy. Đây là một thư viện cho phép chúng ta sử dụng một gói rất phổ biến là SQLAlchemy. Đây là một phần mềm trong nhóm sản phẩm gọi là Object Relational Mapping hay ORM. Các phần mềm trong nhóm này giúp chúng ta giao tiếp với cơ sở dữ liệu thông qua các thực thể như lớp, đối tượng và phương thức thay vi dùng các bảng và ngôn ngữ SQL (Các đại diện tiêu biểu cho nhóm sản phẩm này gồm có Hibernate cho Java, NHibernate hoặc EntityFramework cho .NET framework, …). Công việc chính của các phần mềm ORM là dịch các tác vụ bậc cao thành các lệnh dùng trong cơ sở dữ liệu.
Một đặc điểm rất hay của SQLAlchemy là nó hỗ trợ cho rất nhiều cơ sở dữ liệu quan hệ khác nhau như MySQL, PostgreSQL và SQLite. Điều này rất hữu ích vì nó có nghĩa là bạn có thể phát triển ứng dụng với một hệ cơ sở dữ liệu đơn giản như SQLite – vốn không đòi hỏi việc cài đặt phức tạp, nhưng khi triển khai ứng dụng, bạn có thể chuyển sang một hệ cơ sở dữ liệu khác tốt hơn như là MySQL hay PostgreSQL mà không cần phải thay đổi mã trong ứng dụng của bạn.
Để cài đặt Flask-SQLAlchemy trong môi trường ảo của bạn, hãy kích hoạt nó và chạy lệnh sau:
(myenv) $ pip3 install flask-sqlalchemy
Chuyển đổi dữ liệu
Phần lớn các bài hướng dẫn về cơ sở dữ liệu chỉ dạy cách tạo và sử dụng chúng nhưng lại không đề cập đến vấn đề làm sao để cập nhật cấu trúc của cơ sở dữ liệu sẵn có khi ứng dụng thay đổi. Điều này khó thực hiện bởi vì các thiết kế cơ sở dữ liệu quan hệ có liên quan chặt chẽ đến cấu trúc của dữ liệu. Khi cấu trúc của dữ liệu thay đổi, cơ sở dữ liệu cũng phải được chuyển đổi để thích ứng với cấu trúc mới.
Thư viện mở rộng thứ hai mà chúng ta sẽ sử dụng là Flask-Migrate. Thư viện này là một giao diện của Flask với Alembic – một framework chuyên cho viện chuyển đổi dữ liệu với SQLAlchemy. Việc chuyển đổi cơ sở dữ liệu sẽ làm cho chúng ta mất công hơn một chút khi khởi tạo cơ sở dữ liệu, nhưng đáng giá vì nó sẽ giảm nhiều gánh nặng cho chúng ta trong việc thay đổi cơ sở dữ liệu trong tượng lai.
Quá trình cài đặt thư viện Flask-Migrate hoàn toàn tương tự như các thư viện khác:
(myenv) $ pip3 install flask-migrate
Thiết lập cấu hình cho Flask-SQLAlchemy
Chúng ta sẽ sử dụng cơ sở dữ liệu SQLite cho ứng dụng của chúng ta. SQLite là một hệ cơ sở dữ liệu được sử dụng rộng rãi trong quá trình phát triển các ứng dụng nhỏ hoặc thậm chí một vài ứng dụng lớn. Với SQLite, mỗi cơ sở dữ liệu sẽ được lưu trữ trong một file duy nhất và không đòi hỏi phải cài đặt thêm các phần mềm khác trên máy chủ như trong trường hợp của MySQL và PostgreSQL.
Chúng ta sẽ phải thêm vào một số cấu hình mới trong file config.py:
config.py: Cấu hình cho Flask-SQLAlchemy
|
1 2 3 4 5 6 7 8 |
import os basedir = os.path.abspath(os.path.dirname(__file__)) class Config(object): ... SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL') or \ 'sqlite:///' + os.path.join(basedir, 'app.db') SQLALCHEMY_TRACK_MODIFICATIONS = False |
Thư viện Flask-SQLAlchemy sẽ sử dụng cơ sở dữ liệu tại URL được chỉ định bởi tham số cấu hình SQLALCHEMY_DATABASE_URI. Nếu bạn nhớ lại trong Phần 3, chúng ta có quy ước là thiết lập giá trị cấu hình trong biến môi trường và đồng thời cung cấp một giá trị cố định để làm dự phòng nếu vì lý do nào đó ứng dụng không tìm được biến môi trường. Trong trường hợp này, chúng ta sẽ đặt URL của cơ sở dữ liệu vào biến môi trường DATABASE_URL, và nếu như vì một lý do nào đó biến này không hoạt động, ứng dụng sẽ sử dụng cơ sở dữ liệu app.db trong thư mục chính của nó – cũng là giá trị của biến basedir trong đoạn mã trên.
Tham số SQLALCHEMY_TRACK_MODIFICATIONS sẽ được gán là False bởi vì chúng ta không cần chức năng này của SQLAlchemy – nó sẽ theo dõi và thông báo cho ứng dụng mỗi khi dữ liệu được cập nhật.
Trong ứng dụng của chúng ta, cơ sở dữ liệu sẽ được đại diện bởi một đối tượng gọi là thực thể cơ sở dữ liệu (database instance). Thành phần đảm nhiệm việc chuyển đổi cơ sở dữ liệu cũng sẽ được đại diện bởi một đối tượng khác. Các đối tượng này cần được khởi tạo trong ứng dụng, cụ thể hơn là trong file app/__init__.py:
app/__init__.py: Khởi tạo các đối tượng Flask-SQLAlchemy và Flask-Migrate
|
1 2 3 4 5 6 7 8 9 10 11 |
from flask import Flask from config import Config from flask_sqlalchemy import SQLAlchemy from flask_migrate import Migrate app = Flask(__name__) app.config.from_object(Config) db = SQLAlchemy(app) migrate = Migrate(app, db) from app import routes, models |
Chúng ta thay đổi ba chỗ trong mã ở trên. Đầu tiên, chúng ta thêm một đối tượng tên là db để đại diện cho cơ sở dữ liệu. Tiếp theo chúng ta thêm một đối tượng nữa gọi là migrate để đại diện cho thành phần chuyển đổi dữ liệu. Đây cũng là cách tổng quát để chúng ta khởi tạo và sử dụng các thư viện mở rộng của Flask. Và cuối cũng, chúng ta sẽ tham chiếu đến một module mới gọi là models ở phía cuối của file. Module này sẽ định nghĩa cấu trúc của cơ sở dữ liệu.
Mô hình dữ liệu
Dữ liệu trong các hệ thống cơ sở dữ liệu sẽ được đại diện bởi một tập hợp các lớp, thường được gọi là mô hình dữ liệu (database model). Lớp ORM bên trong của SQLAlchemy sẽ thực hiện các công việc chuyển đổi cần thiết để ánh xạ các đối tượng từ mô hình dữ liệu vào các hàng và bảng trong cơ sở dữ liệu.
Để bắt đầu, chúng ta hãy thử tạo một mô hình cho người sử dụng theo như sơ đồ sau:
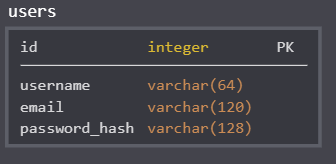
Trường Id thường hiện diện trong hầu hết các mô hình dữ liệu và được sử dụng như là khóa chính (primary key). Mỗi người sử dụng sẽ được gán một giá trị Id duy nhất. Trong đa số các trường hợp, các khóa chính thường được gán giá trị tự động bởi cơ sở dữ liệu, vì vậy chúng ta chỉ cần chỉ định trường id là khóa chính là đủ.
Các trường username, email và password_hash được định nghĩa là các chuỗi (hay là kiểu VARCHAR theo quy ước của cơ sở dữ liệu). Độ dài tối đa của các chuỗi này cũng được xác định để hệ thống cơ sở dữ liệu có thể tối ưu không gian lưu trữ. Ý nghĩa của các trường username và password tương đối dễ hiểu, nhưng chúng ta cần giải thích một chút về trường password_hash. Dù ứng dụng của chúng ta không phải là một ứng dụng hoàn chỉnh, chúng ta vẫn muốn tuần theo những quy tắc bảo mật nhất định. Và một trong những quy tắc cơ bản nhất là không bao giờ lưu trữ mật mã (password) trong cơ sở dữ liệu dưới dạng văn bản (text). Lý do là vì nếu cơ sở dữ liệu bị xâm nhập, hacker sẽ truy nhập được tất cả các mật mã và từ đó có thể lấy tất cả thông tin cá nhân của người sử dụng. Vì vậy, thay vì lưu trữ mật mã dưới dạng văn bản, chúng ta sẽ dùng định dạng băm của mật mã (password hash) – hash là cấu trúc một chiều, chúng ta sẽ không thể chuyển đổi hash thành văn bản gốc – nhờ đó, chúng ta sẽ tránh được tình trạng truy nhập mật khẩu trái phép ngay cả khi cơ sở dữ liệu của chúng ta rơi vào tay của hacker. Chúng ta sẽ thảo luận vấn đề bảo mật kỹ hơn trong các phần sau.
Bây giờ, chúng ta có thể chuyển đổi mô hình dữ liệu người dùng ở trên thành mã chương trình trong file app/models như sau:
app/models.py: Mô hình dữ liệu về người sử dụng
|
1 2 3 4 5 6 7 8 9 10 |
from app import db class User(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), index=True, unique=True) email = db.Column(db.String(120), index=True, unique=True) password_hash = db.Column(db.String(128)) def __repr__(self): return '<User {}>'.format(self.username) |
Lớp User được tạo ra ở trên thừa kế từ lớp db.Model, đây là lớp cơ bản cho tất cả các mô hình dữ liệu trong thư viện Flask-SQLAlchemy. Lớp này đặc tả một số trường là các thực thể của lớp db.Column dưới dạng các biến thuộc lớp. Khi khởi tạo, các trường này, chúng ta cần truyền vào kiểu của dữ liệu trong cơ sở dữ liệu và một số các tham số tùy chọn khác, ví dụ như tham số để chỉ định rằng các trường này là duy nhất (unique) và có chỉ mục (index), các tham số này sẽ giúp cho cơ sở dữ liệu tối ưu hóa quá trình tìm kiếm dữ liệu.
Phương thức __repr__() báo cho trình biên dịch Python biết cách để in ra các thông tin về đối tượng, và rất hữu dụng cho việc dò tìm lỗi (debugging). Chúng ta có thể thấy cách hoạt động của phương thức __repr__() như trong phần minh họa dưới đây:
|
1 2 3 4 |
>>> from app.models import User >>> u = User(username='thai', email='thai@example.com') >>> u <User thai> |
Tạo ra kho lưu trữ cho quá trình chuyển đổi dữ liệu (migration repository)
Mô hình dữ liệu mà chúng ta tạo ra ở trên định nghĩa cấu trúc ban đầu của dữ liệu (schema) mà chúng ta sẽ dùng trong ứng dụng. Nhưng khi chúng ta tiếp tục phát triển ứng dụng về sau, sẽ có những lúc chúng ta sẽ cần thay đổi hay cập nhật cấu trúc này. Để giúp cho quá trình này, Alembic (framework cho việc chuyển đổi dữ liệu được sử dụng trong thư viện Flask-Migrate) sẽ đảm nhiệm việc thay đổi cấu trúc dữ liệu trong cơ sở dữ liệu mà không cần phải tạo lại cơ sở dữ liệu từ đầu.
Để thực thi công việc có vẻ khó khăn này, Alembic có một kho lưu trữ cho quá trình chuyển đổi dữ liệu (migration repository). Đây thực ra là một thư mục có chứa các đoạn mã kịch bản (script) cho việc chuyển đổi dữ liệu. Mỗi khi chúng ta cập nhật cấu trúc dữ liệu, một đoạn mã mới có chứa các thay đổi cần thiết sẽ được thêm vào trong kho lưu trữ này. Để thực hiện việc chuyển đổi cho cơ sở dữ liệu, các đoạn mã này sẽ được thực hiện theo đúng thứ tự mà chúng đã được tạo ra.
Thư viện Flask-Migrate có các lệnh riêng được gọi thông qua lệnh flask. Cho đến giờ, chúng ta đã biết một lệnh flask là flask run. Lệnh này được hỗ trợ trực tiếp từ Flask. Hôm nay chúng ta sẽ dùng thêm một lệnh nữa là flask db, đây là lệnh mở rộng khi chúng ta dùng thư viện Flask-Migrate để thực hiện các thao tác chuyển đổi dữ liệu. Trước hết, hãy tạo một kho lưu trữ chuyển đổi dữ liệu cho ứng dụng của chúng ta bằng lệnh flask db init:
|
1 2 3 4 5 6 7 8 |
(myenv) $ flask db init Creating directory /home/thaipt/Works/Flask/myblog/migrations ... done Creating directory /home/thaipt/Works/Flask/myblog/migrations/versions ... done Generating /home/thaipt/Works/Flask/myblog/migrations/env.py ... done Generating /home/thaipt/Works/Flask/myblog/migrations/README ... done Generating /home/thaipt/Works/Flask/myblog/migrations/script.py.mako ... done Generating /home/thaipt/Works/Flask/myblog/migrations/alembic.ini ... done Please edit configuration/connection/logging settings in '/home/thaipt/Works/Flask/myblog/migrations/alembic.ini' before proceeding. |
Lưu ý rằng lệnh flask cần có biến môi trường FLASK_APP để biết vị trí của ứng dụng Flask. Vì vậy, xin nhắc lại để chạy ứng dụng, chúng ta cần thiết lập biến môi trường FLASK_APP = myblog như đã nói ở Phần 1.
Sau khi chạy lệnh này, bạn sẽ thấy thư mục mới tên là migrations có chứa một số file và một thư mục con của thư mục này tên là versions. Tất cả những file này là một phần trong mã nguồn của bạn và cần được thêm vào hệ thống quản lý mã nguồn của bạn.
Chuyển đổi dữ liệu lần đầu
Khi đã có kho lưu trữ cho chuyển đổi dữ liệu, chúng ta có thể tiến hành thực hiện việc chuyển đổi dữ liệu lần thứ nhất. Quá trình này sẽ tạo ra bảng user trong hệ thống cơ sở dữ liệu tương ứng với mô hình dữ liệu User. Có hai cách để thực hiện việc chuyển đổi dữ liệu: tự động hay thủ công. Với cách chuyển đổi tự động, Alembic sẽ so sánh cấu trúc dữ liệu được định nghĩa bởi mô hình dữ liệu và cơ sở dữ liệu thật sự và tạo ra mã kịch bản (script) để thay đổi cấu trúc của cơ sở dữ liệu cho phù hợp với mô hình dữ liệu. Trong trường hợp này, bởi vì chúng ta chưa tạo ra cơ sở dữ liệu, quá trình chuyển đổi tự động sẽ đưa toàn bộ mô hình dữ liệu User vào mã chuyển đổi. Để bắt đầu quá trình chuyển đổi tự động, chúng ta dùng lệnh flask db migrate như sau:
|
1 2 3 4 5 6 7 |
(myenv) $ flask db migrate -m "Tạo bảng users" INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.autogenerate.compare] Detected added table 'user' INFO [alembic.autogenerate.compare] Detected added index 'ix_user_email' on '['email']' INFO [alembic.autogenerate.compare] Detected added index 'ix_user_username' on '['username']' Generating /home/thaipt/Works/Flask/myblog/migrations/versions/fcf566b5be7f_tao_bang_users.py ... done |
Các dòng trạng thái của lệnh này cho chúng ta biết đại thể Alembic làm việc như thế nào trong quá trình này. Hai dòng đầu tiên chỉ mang tính tham khảo và có thể bỏ qua. Sau đó, Alembic cho biết đã tìm được một bảng user với hai chỉ mục. Tiếp theo, chúng ta cũng thấy được vị trí của mã kịch bản chuyển đổi. Chuỗi fcf566b5be7f là một chuỗi được sinh ra tự động và có giá trị duy nhất (nó sẽ có giá trị khác trên máy của bạn) cho quá trình chuyển đổi. Tham số -m và chuỗi “Tạo bảng users” theo sau là tùy chọn (optional), nó chỉ có tác dụng thêm một dòng mô tả vào mã chuyển đổi.
Mã kịch bản cho chuyển đổi dữ liệu sinh ra sau lệnh này sẽ là một phần trong dự án của bạn và cần được thêm vào hệ thống quản lý mã nguồn mà bạn đang sử dụng. Nếu bạn muốn, bạn có thể xem thử các đoạn mã này. Bạn sẽ thấy rằng nó có hai hàm gọi là upgrade() và downgrade(). Hàm upgrade() sẽ thực hiện việc chuyển đổi và hàm downgrade() sẽ xóa bỏ các thay đổi được tạo ra bởi upgrade(). Điều này cho phép Alembic chuyển đổi dữ liệu tới bất kỳ điểm nào trong lịch sử chuyển đổi – ngay cả khi cần chuyển về các phiên bản cũ hơn nhờ vào hàm downgrade().
Lệnh flask db migrate sẽ không thực hiện bất kỳ thay đổi nào trong cơ sở dữ liệu, nó chỉ sinh ra các đoạn mã kịch bản (script) cần thiết để chạy quá trình này mà thời. Để thực hiện việc chuyển đổi thực sự, chúng ta phải dùng lệnh flask db upgrade như sau:
|
1 2 3 4 |
(myenv) $ flask db upgrade INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.runtime.migration] Running upgrade -> fcf566b5be7f, Tao bang users |
Vì ứng dụng của chúng ta sử dụng cơ sở dữ liệu SQLite, khi lệnh upgrade chạy, nó sẽ tự động khởi tạo cơ sở dữ liệu nếu nó phát hiện file chứa cơ sở dữ liệu không tồn tại (nếu để ý, bạn sẽ thấy file app.db – file có chứa cơ sở dữ liệu của SQLite – được tạo ra sau khi lệnh này chạy xong). Khi làm việc với các hệ cơ sở dữ liệu khác như MySQL hoặc PostgreSQL, bạn phải tạo ra cơ sở dữ liệu trên máy chủ trước khi chạy lệnh upgrade.
Cũng xin lưu ý rằng theo mặc định, Flask-SQLAlchemy sử dụng quy ước đặt tên theo kiểu con rắn (snake-case) cho các bảng trong cơ sở dữ liệu. Vì vậy, nó sẽ tạo ra bảng user cho mô hình dữ liệu User. Tương tự như vậy, nó sẽ đặt tên cho bảng ứng với mô hình dữ liệu AddressAndPhone là address_and_phone. Nếu bạn muốn sử dụng cách đặt tên theo ý bạn, bạn có thể thêm thuộc tính __tablename__ vào trong mô hình dữ liệu và gán tên mà bạn muốn vào đó dưới dạng chuỗi.
Quá trình nâng cấp và giảm cấp cơ sở dữ liệu
Tại thời điểm này, ứng dụng của chúng ta vẫn còn rất sơ khai. Dù vậy, chúng ta cũng nên nói về cách thức chúng ta sẽ dùng cho việc chuyển đổi dữ liệu sau này. Giả sử chúng ta có hai phiên bản của ứng dụng: một trên máy của bạn dùng để phát triển, và một sẽ được dùng để triển khai vào máy chủ chính thức trên mạng mà mọi người có thể sử dụng.
Bây giờ chúng ta sẽ thử xem xét tình huống sau: trong lần phát hành tiếp theo của ứng dụng, bạn đã thay đổi mô hình dữ liệu của bạn – ví dụ như chúng ta sẽ thêm một bảng mới vào cơ sở dữ liệu. Nếu không có quá trình chuyển đổi bạn sẽ cần phải tìm hiểu làm thế nào để thay đổi cấu trúc của cơ sở dữ liệu của bạn trong cả hai môi trường: môi trường phát triển và máy chủ. Và chúng ta sẽ phải tốn rất nhiều công sức cho việc này.
Nhưng với sự hỗ trợ của chuyển đổi dữ liệu, sau khi bạn đã cập nhật mô hình dữ liệu, bạn sẽ tạo ra một mã kịch bản mới (với lệnh flask db migrate). Bạn sẽ cần duyệt lại mã này để chắn chắn rằng không có sai sót nào – bởi vì quá trình tạo ra mã này là tự động – và sau đó thực thi mã này trong môi trường phát triển (với lệnh flask db upgrade). Cuối cùng, bạn sẽ thêm mã này vào hệ thống quản lý mã nguồn.
Khi bạn đã sẵn sàng để phát hành phiên bản tiếp theo của ứng dụng trên môi trường production, bạn chỉ cần lấy mã đã được cập nhật từ hệ thống quản lý mã nguồn. Mã này sẽ bao gồm cả mã kịch bản cho chuyển đổi dữ liệu. Và công việc tiếp theo của bạn chỉ đơn giản là chạy lệnh flask db upgrade. Alembic sẽ tự động phát hiện ra là cơ sở dữ liệu trên môi trường production của bạn chưa được cập nhật với cấu trúc dữ liệu hiện tại và sẽ thực thi tất cả các mã kịch bản kể từ lần phát hành cuối cùng.
Như chúng ta đã thấy, Flask-Migration cũng bao gồm lệnh flask db downgrade để hủy bỏ các thay đổi trên cơ sở dữ liệu đã được thực hiện trước đây. Dù trong thực tế hiếm khi chúng ta phải sử dụng lệnh này trên máy chủ chính thức, nó sẽ rất hữu ích trong môi trường phát triển của chúng ta. Sẽ có lúc bạn tạo ra một một mã kịch bản chuyển đổi nhưng lại phát hiện nó không chạy như ý. Trong những trường hợp như vậy, bạn có thể dùng lệnh downgrade, xóa bỏ các mã kịch bản này và tạo ra các mã kịch bản đúng.
Sơ lược về quan hệ trong cơ sở dữ liệu
Các hệ thống cơ sở dữ liệu quan hệ đảm nhiệm rất tốt việc lưu trữ và thiết lập các mối quan hệ giữa các bản ghi (record). Ví dụ như trong trường hợp một người sử dụng viết một bài trên blog, người sử dụng sẽ được đại diện bởi một bản ghi trong bản (table) users, và bài viết sẽ được đại diện bởi một bản ghi khác trên bảng posts. Cách hiệu quả nhất để biết người nào viết bài nào là thiết lập mối quan hệ giữa hai bản ghi này.
Sau khi mối quan hệ giữa người sử dụng và bài viết được thiết lập, hệ thống cơ sở dữ liệu sẽ có thể tìm ra kết quả cho các truy vấn (query) về mối liên hệ này. Một ví dụ dễ thấy là bạn có một bài viết và muốn tìm ra ai đã viết bài này. Ngược lại, nếu bạn muốn tìm ra các bài viết được thực hiện bởi một tác giả, bạn sẽ phải dùng một truy vấn phức tạp hơn. Flask-SQLAlchemy sẽ hỗ trợ cho chúng ta trong cả hai trường hợp.
Bây giờ hãy mở rộng cơ sở dữ liệu của chúng ta để lưu trữ cả các bài viết để hiểu rõ hơn về các quan hệ. Sau đây là cấu trúc của bảng posts:
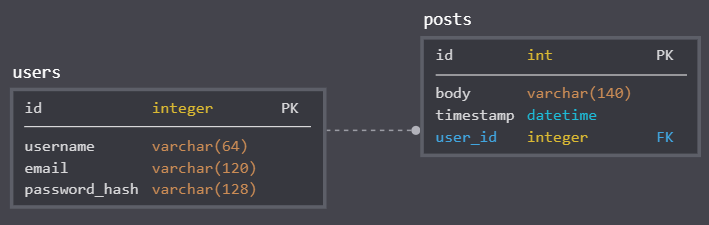
Bảng posts sẽ có trường id (bắt buộc), body và timestamp. Tuy vậy, ngoài các trường này, chúng ta sẽ thêm một trường mới là user_id để liên kết các bài viết với tác giả. Trước đây, chúng ta đã thảo luận về lý do tại sao chúng ta cần sử dụng trường id với vai trò khóa chính cho các bản ghi về người sử dụng, và chúng ta cũng đã biết rằng giá trị của các id phải là duy nhất. Để tạo liên kết giữa các bài viết và tác giả, chúng ta cần thêm tham chiếu đến id của tác giả (cũng là id từ các bản ghi trong bản users) từ bản posts, và đó là lý do tại sao chúng ta cần có trường user_id. Trường này được gọi là một khóa ngoại (foreign key). Sơ đồ trên cho chúng ta thấy vai trò của khóa ngoại trong việc thiết lập liên hệ giữa hai bảng posts và users. Trong trường hợp này, liên hệ giữa hai bảng được gọi là một-nhiều (one-to-many) vì một tác giả (user) có thể viết nhiều bài (post). Nếu bạn vẫn còn cảm thấy không hiểu rõ về quan hệ trong mô hình dữ liệu và cơ sở dữ liệu, bạn có thể tham khảo thêm tại đây.
Chúng ta sẽ cập nhật file app/models.py để tạo mô hình dữ liệu cho các bài viết như sau:
app/models.py: Bảng Posts và liên hệ với bảng User
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from datetime import datetime from app import db class User(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), index=True, unique=True) email = db.Column(db.String(120), index=True, unique=True) password_hash = db.Column(db.String(128)) posts = db.relationship('Post', backref='author', lazy='dynamic') def __repr__(self): return '<User {}>'.format(self.username) class Post(db.Model): id = db.Column(db.Integer, primary_key=True) body = db.Column(db.String(140)) timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow) user_id = db.Column(db.Integer, db.ForeignKey('user.id')) def __repr__(self): return '<Post {}>'.format(self.body) |
Lớp Post sẽ đại diện cho các bài viết của người sử dụng. Trường timestamp dùng để lưu lại thời gian bài viết được tạo ra. Trường này được lập chỉ mục để tối ưu quá trình truy vấn các bài viết. Trong mã để khởi tạo trường này, chúng ta cũng thêm tham số default và gán giá trị trả về từ hàm datetime.utcnow() cho nó. Điều này đồng nghĩa với việc khi chúng ta tạo một đối tượng Post mà không chỉ định thời gian nó được tạo ra, khi ứng dụng lưu bản ghi này vào cơ sở dữ liệu, nó sẽ tự động gán thời điểm mà bản ghi được lưu lại vào trường timestamp. Chúng ta cũng sử dụng giờ UTC cho trường này để bảo đảm rằng ứng dụng sẽ sử dụng thời gian chuẩn và không phụ thuộc vào vị trí địa lý của người sử dụng. Giá trị của timestamp sẽ được chuyển đổi thành thời gian địa phương khi hiển thị cho người sử dụng ở các vị trí khác nhau.
Trường user_id được khởi tạo với vai trò là khóa ngoại của user.id. Nói cách khác, mỗi giá trị của trường này trong bảng posts là một giá trị từ trường id của bảng users. Trong giá trị user.id, chuỗi user đại diện cho tên của bảng tương ứng với mô hình dữ liệu. Tuy nhiên, ở đây có một vài điểm không nhất quán mà chúng ta phải tạm thời chấp nhận. Ví dụ như khi gọi hàm db.relationship(), chúng ta tham chiếu đến mô hình dữ liệu thông qua lớp tương ứng bằng cách dùng tên của nó – bắt đầu bằng chữ hoa, nhưng trong một số trường hợp khác như khi gọi hàm db.ForeignKey(), chúng ta phải sử dụng tên bảng trong cơ sở dữ liệu để tham chiếu đến mô hình dữ liệu tương ứng với tên gọi bằng chữ thường theo quy ước của SQLAlchemy (hoặc là dùng kiểu snake case nếu tên gọi của mô hình dữ liệu là từ ghép).
Lớp User cũng được cập nhật để có thêm trường posts và được khởi tạo với hàm db.relationship(). Đây không phải là một trường thật sự trong cơ sở dữ liệu mà chỉ là một định nghĩa cấp cao để mô tả liên hệ giữa tác giả và bài viết (trường ảo), vì vậy chúng ta không biểu diễn nó trong sơ đồ dữ liệu. Đối với các mối quan hệ một-nhiều, một trường được định nghĩa từ db.relationship ở phía của quan hệ “một” sẽ cho phép truy nhập vào các trường của ở phía “nhiều”. Ví dụ như nếu chúng ta lưu một bản ghi về tác giả trong table u, biểu thức u.posts sẽ thực hiện một truy vấn trong cơ sở dữ liệu để tìm tất cả những bài viết được viết bởi tác giả này. Khi gọi hàm db.relationship, tham số đầu tiên là lớp mô hình đại diện cho phía “nhiều” trong mối quan hệ giữa hai mô hình. Tham số này được truyền dưới dạng một chuỗi được gán tên của lớp mô hình tương ứng sẽ được định nghĩa trong phần tiếp theo của module. Tham số thứ hai (backref) định nghĩa tên của trường sẽ được thêm vào các đổi tượng ở phía “nhiều” (trong trường hợp này là các bài viết hay post) và nhờ đó chúng ta truy nhập ngược lại các đối tượng từ phía “một” trong mô hình quan hệ. Cụ thể là nó sẽ cho phép chúng ta dùng biểu thức post.author để tìm ra tác giả của một bài viết nào đó. Tại thời điểm này, chúng ta sẽ tạm thời lướt qua tham số tiếp theo là lazy và sẽ trở lại với tham số này trong các phần tiếp theo. Đừng lo nếu bạn vẫn thấy còn cảm thấy chưa hiểu rõ các chi tiết này, bạn sẽ thấy rõ ràng hơn qua các ví dụ minh họa tiếp theo sau.
Vì chúng ta vừa thay đổi mô hình dữ liệu, chúng ta cần tạo ra mã chuyển đổi mới:
|
1 2 3 4 5 6 |
(myenv) $ flask db migrate -m "Tạo bảng posts" INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.autogenerate.compare] Detected added table 'post' INFO [alembic.autogenerate.compare] Detected added index 'ix_post_timestamp' on '['timestamp']' Generating /home/thaipt/Works/Flask/myblog/migrations/versions/f0db34c99253_tao_bang_posts.py ... done |
Và tiếp theo, chúng ta cần tiến hành quá trình chuyển đổi bằng cách chạy các mã vừa sinh ra ở trên:
|
1 2 3 4 |
(myenv) $ flask db upgrade INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.runtime.migration] Running upgrade fcf566b5be7f -> f0db34c99253, Tao bang posts |
Đừng quên thêm các mã chuyển đổi mới này vào hệ thống quản lý mã nguồn của bạn nhé.
Thực hành
Suốt từ đầu đến giờ, chúng ta hầu như chỉ nói về việc định nghĩa dữ liệu, thật là chán phải không? Bây giờ chúng ta hãy thực tập một chút để làm quen với cách hoạt động của cơ sở dữ liệu và Python. Bạn hãy gọi trình biên dịch Python bằng lệnh python và hãy chắc rằng bạn đã kích hoạt môi trường ảo trước khi chúng ta bắt đầu.
Tại dấu nhắc lệnh của trình biên dịch Python, hãy tham chiếu (import) đến các thư viện và đối tượng trong mô hình dữ liệu của chúng ta:
|
1 2 |
>>> from app import db >>> from app.models import User, Post |
Hãy thử tạo một người sử dụng mới:
|
1 2 3 |
>>> u = User(username='thai', email='thai.pham@example.com') >>> db.session.add(u) >>> db.session.commit() |
Ở đây chúng ta thấy có một khái niệm mới là session (phiên làm việc) khi chúng ta sử dụng các hàm trong db.session. Một session đóng vai trò cầu nối giữa người sử dụng (hay ứng dụng) và cơ sở dữ liệu, nó chứa tất cả các đối tượng và các yêu cầu từ người sử dụng đến cơ sở dữ liệu. Tất cả các yêu cầu đến cơ sở dữ liệu được thêm vào session qua hàm session.add() sẽ được lưu giữ trong session nhưng sẽ không được thực thi cho đến khi chúng ta gọi hàm session.commit(). Hoặc nếu cần hủy bỏ các yêu cầu này, chúng ta có thể gọi hàm session.rollback(). Chúng ta chỉ cần ghi nhớ là các thay đổi trong cơ sở dữ liệu chỉ xảy ra sau khi chúng ta gọi hàm session.commit() hoặc session.rollback(). Session bảo đảm rằng dữ liệu trong cơ sở dữ liệu luôn toàn vẹn. Bạn sẽ hiểu rõ hơn về session nếu bạn gặp phải tình huống phải cập nhật dữ liệu trong nhiều bảng cùng lúc và các dữ liệu này phụ thuộc với nhau, khi đó, nếu quá trình cập nhật dữ liệu gặp trục trặc với một bảng nào đó, chúng ta cần phải hủy bỏ toàn bộ quá trình và bảo đảm rằng không có dữ liệu liên quan nào được ghi vào cơ sở dữ liệu, session cho phép chúng ta thực hiện điều này một cách tự động.
Tiếp theo, chúng ta hãy thêm một người sử dụng nữa:
|
1 2 3 |
>>> u = User(username='nguyen', email='nguyen@example.com') >>> db.session.add(u) >>> db.session.commit() |
Đến đây, cơ sở dữ liệu của chúng ta có thể trả lời cho truy vấn tìm kiếm tất cả người sử dụng trong hệ thống:
|
1 2 3 4 5 6 7 8 |
>>> users = User.query.all() >>> users [<User thai>, <User nguyen>] >>> for u in users: ... print(u.id, u.username) ... 1 thai 2 nguyen |
Tât cả các đối tượng mô hình dữ liệu đều có thuộc tính query để thực hiện truy vấn. Truy vấn cơ bản nhất là tìm tất cả những đối tượng thuộc cùng một lớp với hàm all(). Lưu ý là trường id sẽ được tự động gán cá giá trị số nguyên theo thứ tự tăng dần (ở đây là 1 và 2) khi chúng ta thêm các dữ liệu mới vào.
Sau đây chúng ta sẽ thử tìm thông tin về người sử dụng qua Id của họ:
|
1 2 3 |
>>> u = User.query.get(1) >>> u <User thai> |
Vậy nếu chúng ta muốn thêm một bài viết thì sao?
|
1 2 3 4 |
>>> u = User.query.get(1) >>> p = Post(body='my first post!', author=u) >>> db.session.add(p) >>> db.session.commit() |
Chúng ta không gán giá trị cho trường timestamp vì giá trị này có được gán giá trị mặc định (bạn còn nhớ hàm datetime.utcnow không?). Thế còn trường user_id thì sao? Bạn có nhớ chúng ta đã dùng hàm db.relationship để thêm biến posts vào lớp User không? Khi gọi hàm này, chúng ta cũng đồng thời gán trường ảo author để sử chúng ta có thể sử dụng thay vì dùng Id của người dùng. SQLAlchemy làm rất tốt công việc này khi cho phép chúng ta sử dụng các trừu tượng thay vì sử dụng trực tiếp các khóa ngoại để biểu diễn mối liên hệ giữa các mô hình dữ liệu.
Để kết thúc mục này, chúng ta sẽ xem qua vài ví dụ truy vấn dữ liệu nữa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
>>> # Tìm tất cả bài được viết bởi một user >>> u = User.query.get(1) >>> u <User thai> >>> posts = u.posts.all() >>> posts [<Post my first post!>] >>> # tương tự như vậy, nhưng lần này là một user không có bài viết >>> u = User.query.get(2) >>> u <User nguyen> >>> u.posts.all() [] >>> # in ra tên tác giả và toàn bộ các bài viết >>> posts = Post.query.all() >>> for p in posts: ... print(p.id, p.author.username, p.body) ... 1 thai my first post! >>> # tìm tất cả các user theo thứ tự abc đảo ngược >>> User.query.order_by(User.username.desc()).all() [<User thai>, <User nguyen>] |
Nếu bạn muốn tìm hiểu thêm về các ùy chọn khi truy vấn dữ liệu, bạn có thể tham khảo các tài liệu trực tuyến của Flask-SQLAlchemy.
Và cuối cùng, chúng ta hãy thử xóa dữ liệu về người sử dụng và bài viết mà chúng ta đã tạo ra để dọn trống cơ sở dữ liệu cho phần tiếp theo:
|
1 2 3 4 5 6 7 8 9 |
>>> users = User.query.all() >>> for u in users: ... db.session.delete(u) ... >>> posts = Post.query.all() >>> for p in posts: ... db.session.delete(p) ... >>> db.session.commit() |
Ngữ cảnh lệnh
Bạn có nhớ chúng ta đã làm gì ở đầu bài học trước không? Chúng ta đã gọi trình biên dịch Python và sau đó, thực hiện câu lệnh để tham chiếu (import) như sau:
|
1 2 |
>>> from app import db >>> from app.models import User, Post |
Trong quá trình viết ứng dụng, bạn sẽ phải kiểm tra nhiều thứ qua chế độ dòng lệnh của Python (shell). Vì vậy, việc cứ phải lặp đi lặp lại lệnh import như trên sẽ rất mệt. Để giúp chúng ta, Flask cung cấp một lệnh rất hữu ích: flask shell. Lệnh shell là lệnh quan trọng thứ hai trong Flask, sau lệnh run. Lệnh này sẽ bắt đầu chế độ dòng lệnh của Python với ngữ cảnh (context) của ứng dụng. Bạn có thể hiểu rõ hơn về ngữ cảnh qua ví dụ sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
(myenv) $ python >>> app Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'app' is not defined >>> (myenv) $ flask shell >>> app Python 3.7.3 (default, Apr 3 2019, 05:39:12) [GCC 8.3.0] on linux App: app [production] Instance: /home/thaipt/Works/Flask/myblog/instance >>> |
Trong một phiên làm việc bình thường, trình biên dịch Python không nhận ra app là gì vì nó chưa được tham chiếu. Nhưng khi bạn gọi flask shell, nó sẽ tự động tham chiếu đến thực thể của ứng dụng và nhờ đó biết app là gì. Cái hay ở đây là bạn có thể thiết lập sao cho ngoài việc tự động tham chiếu đến app, flask shell còn có thể tham chiếu đến các đối tượng khác.
Vì vậy, chúng ta sẽ giới thiệu thêm một hàm nữa trong myblog.py để tạo ra một ngữ cảnh lệnh để tự động tham chiếu đến tất cả các đối tượng cần thiết trong ứng dụng của chúng ta như cơ sở dữ liệu và mô hình dữ liệu như sau:
|
1 2 3 4 5 6 |
from app import app, db from app.models import User, Post @app.shell_context_processor def make_shell_context(): return {'db': db, 'User': User, 'Post': Post} |
Decorator app.shell_context_processor sẽ đăng ký hàm này với vai trò là hàm ngữ cảnh lệnh. Khi chúng ta thực hiện lệnh flask shell, nó sẽ gọi hàm này và đăng ký các đối tượng được hàm này trả về với ngữ cảnh lệnh. Lưu ý là giá trị trả về của hàm này có kiểu Dictionary chứ không phải là list vì chúng ta cần gán tên cho các đối tượng trả về này và sử dụng nó trong các lệnh.
Sau khi đã tạo hàm xử lý ngữ cảnh lệnh như trên, bạn có thể làm sử dụng trực tiếp các đối tượng và hàm từ cơ sở dữ liệu mà không cần phải tham chiếu đến chúng:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
(myenv) $ flask shell Python 3.7.3 (default, Apr 3 2019, 05:39:12) [GCC 8.3.0] on linux App: app [production] Instance: /home/thaipt/Works/Flask/myblog/instance >>> db <SQLAlchemy engine=sqlite:////home/thaipt/Works/Flask/myblog/app.db> >>> User <class 'app.models.User'> >>> Post <class 'app.models.Post'> >>> |
Nếu bạn gặp lỗi NameError khi sử dụng các đối tượng db, User và Post như trong ví dụ trên, điều đó có nghĩa là hàm make_shell_context() đã không được đăng ký thành công với Flask. Lý do thường gặp nhất là do bạn quên chỉ định biến môi trường FLASK_APP=myblog.py, hãy xem lại Phần 1 để biết cách khai báo biến này và làm sao để thêm biến này vào file .flaskenv.
Chúng ta sẽ kết thúc phần này ở đây. Hẹn gặp bạn trong phần tiếp theo.
cho em hỏi là sao lại phải để dòng ‘from app import routes, models’ ở cuối được không ạ, em thử đem dòng này lên đầu để thì nó k chạy ạ.
Chào bạn,
Lý do phải để ‘from app import routes, model’ là để tránh tình trạng tham chiếu vòng (circular imports) bởi vì các module routes và model cần phải tham chiếu đến biến app được khai báo trong file __init__.py. Tôi có giải thích điều này trong Phần 1, bạn có thể xem lại.
UserWarning: Neither SQLALCHEMY_DATABASE_URI nor SQLALCHEMY_BINDS is set. Defaulting SQLALCHEMY_DATABASE_URI to “sqlite:///:memory:”
Lỗi này a giúp đỡ, đã dò kỹ code
Chào bạn,
Theo thông báo lỗi này thì SQLAlchemy không tìm được các thông số cần thiết để kết nối với database. Để khắc phục, bạn cần kiểm tra lại đoạn code này trong file app/__init__.py:
app = Flask(__name__)app.config.from_object(Config)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
Bạn cần có đủ bốn dòng mã lệnh trên và sắp xếp theo đúng trình tự như trên. Nếu bạn sắp sai thứ tự các dòng mã trên ví dụ như đặt dòng lệnh
db = SQLAlchemy(app)trước dòng lệnhapp.config.from_object(Config), bạn sẽ nhận được thông báo lỗi như bạn đã thấy.Em có 3 chổ chưa hiểu lắm, anh giải thích giùm em với được không ạ.
1. ở hàm “posts = db.relationship(‘Post’, backref=’author’, lazy=’dynamic’)” trong bảng user khi mình khai báo vậy có nghĩa là gì ạ. vì em thấy anh có gọi “p = Post(body=’my first post!’, author=u)” thì nó tự lấy trường id trong user table và điền vào đúng cột user_id trong post table.
2. Sao khi gọi hàm “posts = u.posts.all()” khi ta in ra post chỉ có mỗi body vậy anh?
3. Còn 1 chổ nữa là khi tạo bảng lần đầu anh gọi lệnh flask
db migrate -m "Tạo bảng users"thì nó có tạo ra 1 bảng tên làalembic_versiontrong database chứ không phải như anh nói ở trên làLệnh flask db migrate sẽ không thực hiện bất kỳ thay đổi nào trong cơ sở dữ liệu, nó chỉ sinh ra các đoạn mã kịch bản (script) cần thiết để chạy quá trình này mà thời.Anh giúp em với ạ. em cám ơn anh.
Câu thứ 2 em mới nhớ ra là cái hàm “def __repr__(self)” trong class Post in ra ạ, còn câu hỏi đầu tiên em chưa hiểu được, anh giúp em với ạ.
Chào bạn,
1. Như tôi đã để cập trong bài viết, quan hệ giữa “User” và “Post” là quan hệ 1-nhiều. Vì vậy, theo quy ước của SQLAlchemy, bạn phải truyền các tham số cho hàm db.relationship như trên. Tôi có mô tả ý nghĩa của các tham số trong bài viết ngay sau phần mã nguồn, bạn đọc kỹ lại nhé.
2. Bạn đã tìm ra lý do là bởi vì hàm __repr__(self).
3. Bảng “alembic_version” mà bạn thấy chỉ là một bảng dùng riêng bởi Alembic và không liên quan đến các bảng mà bạn định nghĩa qua mô hình dữ liệu trong ứng dụng của bạn. Đó là lý do tôi đã nói như trên.